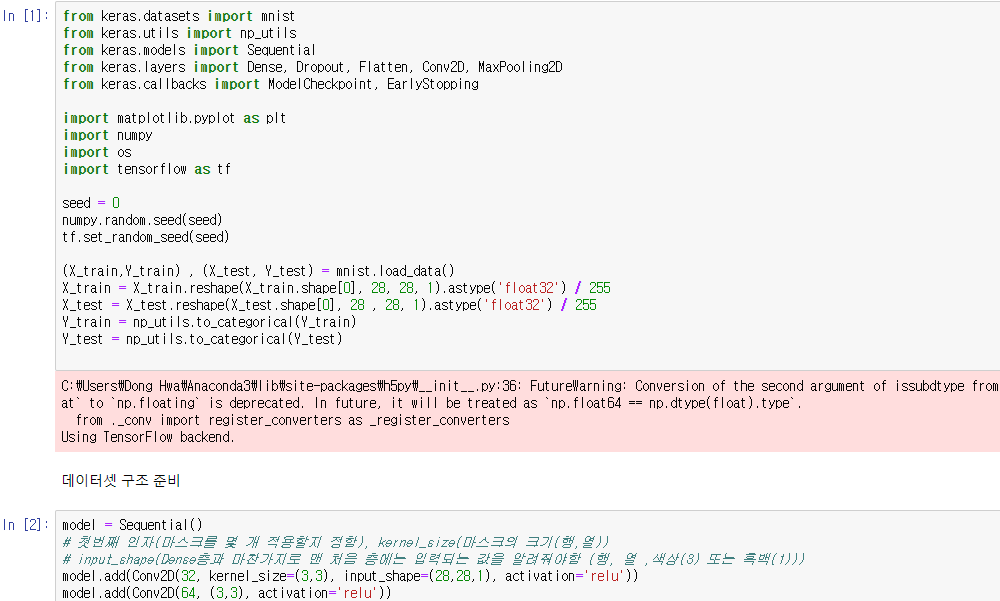
이번에 사용할 데이터셋은 MNIST 데이터셋!
MNIST 데이터셋은 미국 국립표준기술원이 고등학생과 인구조사국 직원들이 쓴 손글씨를 이용해 만든 데이터로 구성되어 있다. 7만개의 글자 이미지에 각각 0부터 9까지 이름표를 붙인 데이터셋으로
머신러닝을 배우는 사람이 자신의 알고리즘과 다른 알고리즘의 성과(Accuracy)를 비교해 보고자 한 번씩 도전하는 유명한 데이터셋!(ex. 캐글)
그럼 과연 지금까지 배운 딥러닝 기술들을 이용해 이 손글씨 이미지를 얼마나 예측할까?


저번 장에서는 학습셋의 정확도를 그래프로 그렸다면 이번에는 학습셋의 오차를 그래프로 표현했을 뿐 저번 장과 매우 비슷!

20번째 실행에서 멈춘 것을 확인할 수 있다 => 베스트 모델은 10번째 에포크!
이 모델의 테스트셋에 대한 정확도는 97.61%.
학습셋의 오차는 파란색 그래프, 테스트셋의 오차는 빨간색 그래프로 과적합이 심하게 일어나기 전에 학습을 끝낸 모습을 볼 수 있음.

앞서 97.61%의 정확도를 보인 딥러닝 프레임은 하나의 은닉층을 둔 아주 단순한 모델을 도식화한 그림이다.
딥러닝은 이러한 기본 모델을 바탕으로 프로젝트의 목젂에 맞춰서 어떤 옵션, 어떤 층을 추가하느냐에 따라 성능이 좋아지는데 지금부터는 기본 딥러닝 프레임에 이미지 인식 분야에서 강력한 성능을 보이는 컨볼루션 신경망(Convolutional Neural Network, CNN)을 얹어보자!

이 그림은 컨볼루션 신경망의 과정을 나타낸 것이다.
컨볼루션 신경망은 입력된 이미지에서 다시 한번 특징을 추출하기 위해 마스크(필터, 윈도 또는 커널)를 도입하는 기법이다.
보이는 것과 같이 마스크에는 가중치가 들어가 있는데 마스크의 가중치로 원래 있던 값을 곱해주면서 나온 값을 정리하면 새롭게 만들어지는 층이 생긴다.
이 층을 컨볼루션(합성곱)이라고 부른다.
컨볼루션을 만들면 입력 데이터로부터 더욱 정교한 특징을 추출할 수 있는데 이러한 마스크를 여러 개 만들 경우 여러 개의 컨볼루션이 만들어짐. 케라스에서 컨볼루션 층을 추가하는 함수는 Conv2D()
지금 구현한 컨볼루션 층을 통해 이미지 특징을 도출했는데 결과가 여전히 크고 복잡하면 이를 다시 축소해야 한다. 이 축소 과정을 풀링(pooling) 또는 서브 샘플링이라고 하는데 풀링 기법 중 가장 많이 사용되는 방법이 맥스 풀링이다.
맥스 풀링은 정해진 구역 안에서 가장 큰 값만 다음 층으로 넘기고 나머지는 버림!
이 과정을 거쳐 밑의 그림처럼 불필요한 정보를 간추린다.

그리고 노드가 많아지거나 층이 많아진다고 학습이 무조건적으로 좋아지지 않는다는 건 과적합을 배울 때 epoch가 많아진다고 좋아지지 않는다는 점에서 유추해낼 수 있는데 이 과정을 도와주는 모델 기법 중에 간단하지만 효과가 큰 기법이 바로 드롭 아웃(drop out) 기법이다.
드롭아웃은 은닉층에 배치된 노드 중 일부를 임의로 꺼주는 데 이렇게 랜덤하게 노드를 꺼 학습 데이터에 지나치게 치우쳐서 학습하지 않게 케라스가 손쉽게 적용하도록 도와준다.
이제 Dense()함수를 이용해 만들었던 기본 층을 연결하기 전에 컨볼루션 층이나 맥스 풀링은 주어진 이미지를 2차원 배열인 채로 다룬다는 점을 생각해 1차원으로 바꿔주는 함수 Flatten()함수를 사용해 1차원으로 바꿔준 다음에 연결해야 한다!



지금까지 배운 컨볼루션 신경망, 맥스 풀링, 드롭 아웃, 플래튼기법, EarlyStopping함수를 통해
이 딥러닝 모델의 정확도는 99.21%까지 올라갔으며 그래프를 봤을 때 과적합이 많이 일어나기 전에 학습을 멈춘 사실을 확인할 수 있다!
이제 드디어 마지막 장인 순환 신경망만 남았다!
'딥러닝' 카테고리의 다른 글
| 모두의 딥러닝 (12) - 시퀀스 배열로 다루는 순환 신경망 (0) | 2019.12.25 |
|---|---|
| 모두의 딥러닝 (10) - 베스트 모델 만들기 (0) | 2019.12.24 |
| 모두의 딥러닝 (9) - 과적합 피하기 (0) | 2019.12.24 |
| 모두의 딥러닝 (8) - 다중 분류 문제 해결하기 (0) | 2019.12.24 |
| 모두의 딥러닝 (7) - 데이터 다루기 (0) | 2019.12.24 |



